Abstract |
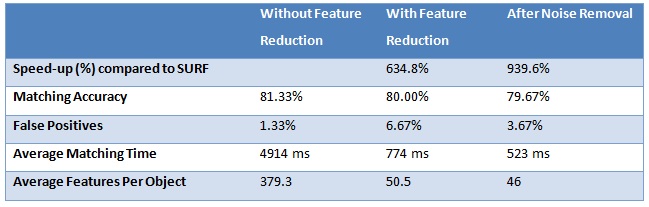
The volume of video media on the internet and from other sources is increasing at a rapid rate. The existing analysis, storage, retrieval, indexing and searching techniques are unable to cope with this huge volume of information. Moreover, there is no efficient way of extracting information from this huge pool. In this lieu, we propose Generating Action Tags and Videos (ViTAG), a system for generating scene descriptions of simple car and bike videos. ViTAG aims to describe simple car and bike videos using object and action recognition. We propose a three step process for generating these scene descriptions. Key Frame ExtractionThe nature of video data does not make it a good candidate for conventional retrieval, indexing and storage techniques due to redundancy. Video summarization is a method to reduce this redundancy. In this paper we present a technique for video summary generation using key frame extraction called Key Frame Extractor (KFE). KFE uses 2D auto-correlation, color histogram comparison and moment invariants for key frame extraction. An adaptive formula is used to make KFE partially tolerant to lighting condition changes. KFE allows a tradeoff in computation, memory complexity and accuracy of key frame extraction. The video summarization results compare very well to the TRECVID 2007 benchmark and CMU's submission to TRECVID 2007 [TE-ICPR10]. Object RecognitionObject recognition is one of the most important problems in computer vision, with wide ranging applications such as content based search, automated surveillance, action recognition etc. In this paper we present a framework for object recognition and pose estimation using SURF features. In this framework we make four novel contributions. Our feature-reduction process allows a speed-up of matching speed-up of 634.8% by using only the most repeatable features for matching. The noise-reduction process allows a further increase in matching speed-up reducing the false positive rates by 50%. A modified definition of the second-neighbor in the in the nearest neighbor ratio matching strategy allows matching with increased reliability. We also introduce a hierarchal approach for feature database storage that presents an easy way for pose estimation of objects. [TE-IPCV10] Scene and Action Recognition in VideosIn progress |
| [Back] |
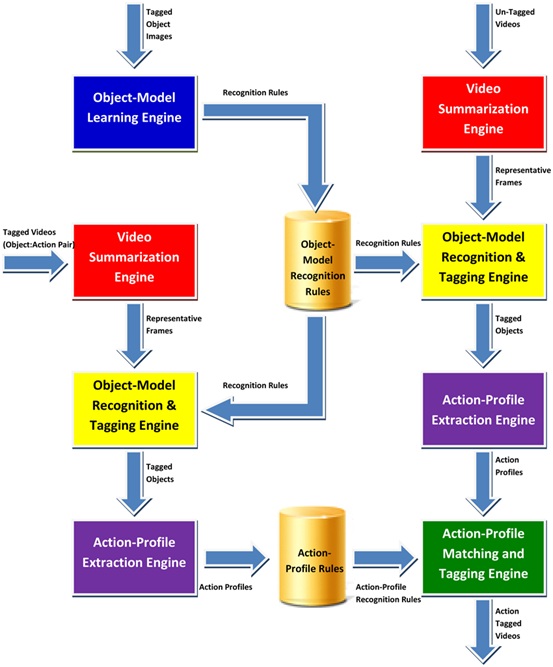
Framework |
Figure 1: Learning Framework for ViTAG |
| [Back] |
Results | ||||||||||||||||||||||||||||||||||||||||
This section presents the results of different components of ViTAG. Key Frame Extraction
| ||||||||||||||||||||||||||||||||||||||||
| [Back] |

References |
[TE-ICPR10] T. Tariq, N. Ejaz. Video Summarization using Key Frame Extraction. Submitted to ICPR 2010. |
| [Back] |
About Us | ||||
|
||||
| [Back] |

